Abstract
3D Visual Grounding (3DVG) is an essential capability for embodied AI, requiring agents to localize objects in 3D scenes based on natural language descriptions. Recent zero-shot methods leverage 2D vision-language models (LVLMs). However, they often rely on existing sets of multi-view images and struggle with the limited semantic and spatial details provided by standard 3D segmentation tools.
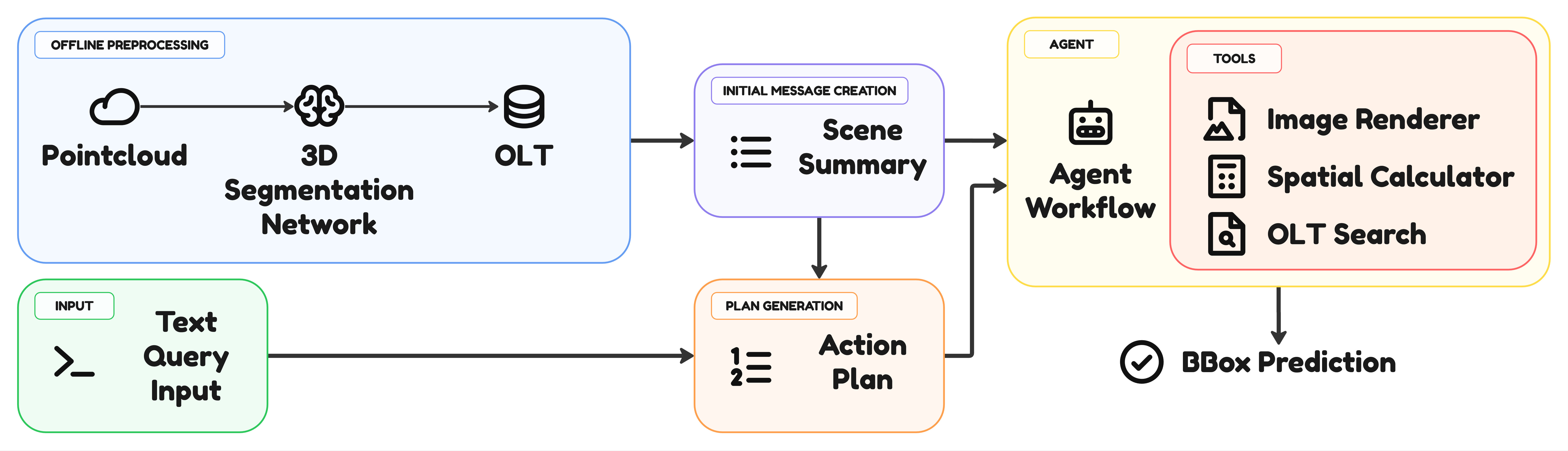
We present AgentGrounder, a zero-shot 3D visual grounding framework that operates directly on colored point clouds without task-specific 3D training. Our approach follows a two-stage design: (1) an offline stage that applies a 3D model to build an Object Lookup Table (OLT) with instance IDs, semantic labels, and 3D bounding boxes; and (2) an online tool-driven agent that decomposes each query, retrieves only relevant candidates from the OLT, performs geometric scoring, and triggers image rendering on demand when additional visual evidence (e.g., color, material, or viewpoint-sensitive cues) is required.
Compared with fixed anchor-target matching pipelines, this design reduces cascading matching errors and improves context-window efficiency by avoiding prompts overloaded with irrelevant objects. We evaluate on ScanRefer and Nr3D under a zero-shot setting and observe consistent improvements over SeeGround in our setup, including +2.5% Acc@0.5 on ScanRefer and +6.3% on Nr3D, with a notable +6.3% gain on Nr3D view-independent queries. These results show that combining selective retrieval, geometric reasoning, and adaptive visual inspection yields a practical and robust foundation for open-vocabulary 3D grounding.